Auto Scaling Spark in Kubernetes - Part 3 : Scaling Spark Workers
Kubernetes makes it easy to run services on scale. With kubernetes abstractions, it’s easy to setup a cluster of spark, hadoop or database on large number of nodes. Kubernetes takes care of handling tricky pieces like node assignment,service discovery, resource management of a distributed system. We have discussed how it can be used for spark clustering in our earlier series.
As the services are becoming more and more dynamic, handling resource needs statically is becoming challenge. With cloud being prevalent, users expect their infrastructure to scale with usage. For example, spark cluster on kubernetes should be able to scale up or down depending upon the load.
Kubernetes system can scaled manually by increasing or decreasing the number of replicas. You can refer to this post for more information. But doing this manually means lot of work. Isn’t it better if kubernetes can auto manage the same?
Kubernetes Horizontal Pod AutoScaler(HPA) is one of the controller in the kubernetes which is built to the auto management of scaling. It’s very powerful tool which allows user to utilize resources of the cluster effectively.
In this series of post, I will be discussing about kubernetes HPA with respect to auto scaling spark. This is the third post in the series which talks about how to auto scale the spark cluster. You can find all the posts in the series here.
Registering the Horizontal Pod AutoScaler
We can register a HPA for spark-worker deployment using below command.
kubectl autoscale deployment spark-worker --max=2 --cpu-percent=50In above command we specified below information
-
Deployment is spark-worker
-
Maximum number of replicas is 2
-
Threshold is 50 percent cpu usage
Get current State of HPA
Once we create the HPA we can see the current status using below command
kubectl get hpaThe result will look as below
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
spark-worker Deployment/spark-worker 0%/50% 1 2 1 4h43mAs you can see, the current state says the load is 0 as there is nothing running in the spark layer.
Describing HPA
The above command just gives the high level information. If we want to know more, we can run the describe command to get all the events.
kubectl describe hpa spark-workerThe result looks as below
Name: spark-worker
Namespace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Sun, 27 Oct 2019 11:30:50 +0530
Reference: Deployment/spark-worker
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 0% (1m) / 50%
Min replicas: 1
Max replicas: 2
Deployment pods: 1 current / 1 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ReadyForNewScale recommended size matches current size
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited True TooFewReplicas the desired replica count is less than the minimum replica count
Events: <none>The conditions field of the output says the current state.
Running Dynamic Allocated Spark Job
Let’s run the spark pi example in dynamic allocation mode. The dynamic allocation mode of spark starts with minimum number of executors. But as the more number of tasks are schedule it will start requesting the more executors. This intern should request more resources from kubernetes which will kick in the auto scaling.
Run the below command from spark-master container.
/opt/spark/bin/spark-submit --master spark://spark-master:7077 --conf spark.shuffle.service.enabled=true --conf spark.dynamicAllocation.enabled=true --class org.apache.spark.examples.SparkPi /opt/spark/examples/jars/spark-examples_2.11-2.1.0.jar 10000Observing the Auto Scale in HPA
Once the spark jobs start running, the cpu usage will go higher. We can start describing the HPA state using below command to see did the auto scaling kick in. You need to keep running this command for 1-2 minutes to see the changes.
kubectl describe hpa spark-workerYou should see below result after sometime
Deployment pods: 1 current / 2 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True SucceededRescale the HPA controller was able to update the target scale to 2
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited False DesiredWithinRange the desired count is within the acceptable range
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 4s (x2 over 4h52m) horizontal-pod-autoscaler New size: 2; reason: cpu resource utilization (percentage of request) above targetHere you can see the auto scaling kicked in. You can confirm by spark UI also.
Observing Auto Scaling in Spark UI
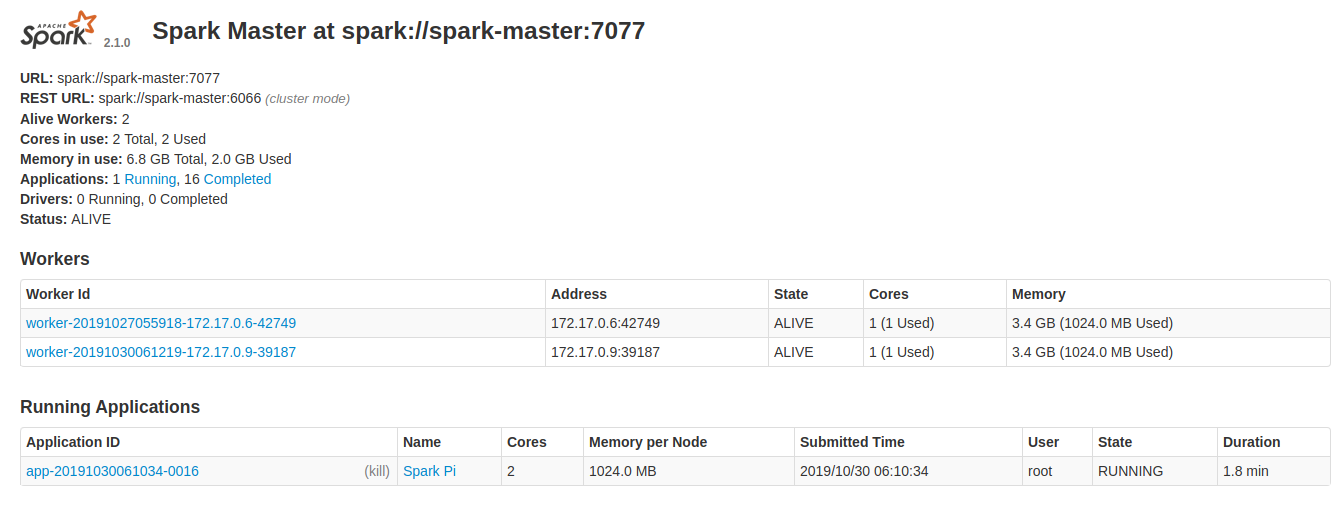 .
.
In the above image, you can observe that they are two workers are running now.
Cool Down of Spark Scaling
The pods that are allocated with kept for 5mins by default. After this cool down time they will be released.
Conclusion
In this post we discussed how to setup HPA for the spark worker. This shows how we can automatically scale our spark cluster with the load.