Auto Scaling Spark in Kubernetes - Part 2 : Spark Cluster Setup
Kubernetes makes it easy to run services on scale. With kubernetes abstractions, it’s easy to setup a cluster of spark, hadoop or database on large number of nodes. Kubernetes takes care of handling tricky pieces like node assignment,service discovery, resource management of a distributed system. We have discussed how it can be used for spark clustering in our earlier series.
As the services are becoming more and more dynamic, handling resource needs statically is becoming challenge. With cloud being prevalent, users expect their infrastructure to scale with usage. For example, spark cluster on kubernetes should be able to scale up or down depending upon the load.
Kubernetes system can scaled manually by increasing or decreasing the number of replicas. You can refer to this post for more information. But doing this manually means lot of work. Isn’t it better if kubernetes can auto manage the same?
Kubernetes Horizontal Pod AutoScaler(HPA) is one of the controller in the kubernetes which is built to the auto management of scaling. It’s very powerful tool which allows user to utilize resources of the cluster effectively.
In this series of post, I will be discussing about HPA with respect to auto scaling spark. This is the second post in the series which talks about how to setup spark cluster to use the auto scaling. You can find all the posts in the series here.
Spark Cluster Setup on Kubernetes
In earlier series of posts we have discussed how to setup the spark cluster on kubernetes. If you have not read it, read it in below link before continuing.
Spark Cluster Setup on Kubernetes.
Enabling Metrics Server in Minikube
As we discussed in earlier post, metrics server is an important part of the auto scaling. In normal kubernetes clusters, it’s enabled by default. But if you are using minikube to test the HPA you need to enabled it explicitly.
The below is the command to enable. This needs minikube restart.
minikube addons enable metrics-serverOnce it’s enabled, you should be able to see it in the list of addons.
minikube addons list- addon-manager: enabled
- dashboard: enabled
- default-storageclass: enabled
- efk: disabled
- freshpod: disabled
- gvisor: disabled
- heapster: disabled
- helm-tiller: disabled
- ingress: disabled
- ingress-dns: disabled
- logviewer: disabled
- metrics-server: enabled
- nvidia-driver-installer: disabled
- nvidia-gpu-device-plugin: disabled
- registry: disabled
- registry-creds: disabled
- storage-provisioner: enabled
- storage-provisioner-gluster: disabledDefining the Resource Usage For Spark Worker
In our spark setup, we need to auto scale spark worker. To auto scale the same, we need to define the it’s resource needs as below.
Restricting at Pod Level
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
name: spark-worker
name: spark-worker
spec:
replicas: 1
selector:
matchLabels:
name: spark-worker
template:
metadata:
labels:
name: spark-worker
spec:
containers:
- image: spark-2.1.0-bin-hadoop2.6
imagePullPolicy : "IfNotPresent"
name: spark-worker
ports:
- containerPort: 7078
protocol: TCP
resources:
limits:
cpu: "1"
requests:
cpu: "1"
command:
- "/bin/bash"
- "-c"
- "--"
args :
- './start-worker.sh; sleep infinity'In above YAML, we have request for the single cpu for every worker in our cluster.
Restricting at Spark Level
By default spark doesn’t respect the resource restriction set by kubernetes. So we need to pass this information when we start the slave. So the below changes are done to our start-worker.sh.
#!/bin/sh
. /start-common.sh
/opt/spark/sbin/start-slave.sh --cores 1 spark://spark-master:7077In above code, –cores 1 will tell to the spark that this slave should use only one core.
Enabling External Shuffle Service
To use the automatically scaled pods, we need to run the spark in dynamic allocation mode. We will talk more about this mode in next post. One of the pre requisite for the dynamic allocation is external shuffle service. This is enabled in each worker node using below configuration in spark-default.conf.
spark.shuffle.service.enabled trueRebuilding the Docker Image
As we done number of changes to the our setup, we need to rebuild the docker image. You can read about building the image here.
Starting the Cluster
Now we have done all the necessary changes. We can start the cluster. You can follow steps laid out here for the same.
The State of the Cluster
Once the cluster is successfully started, you should be able to see one worker in spark master as shown below image.
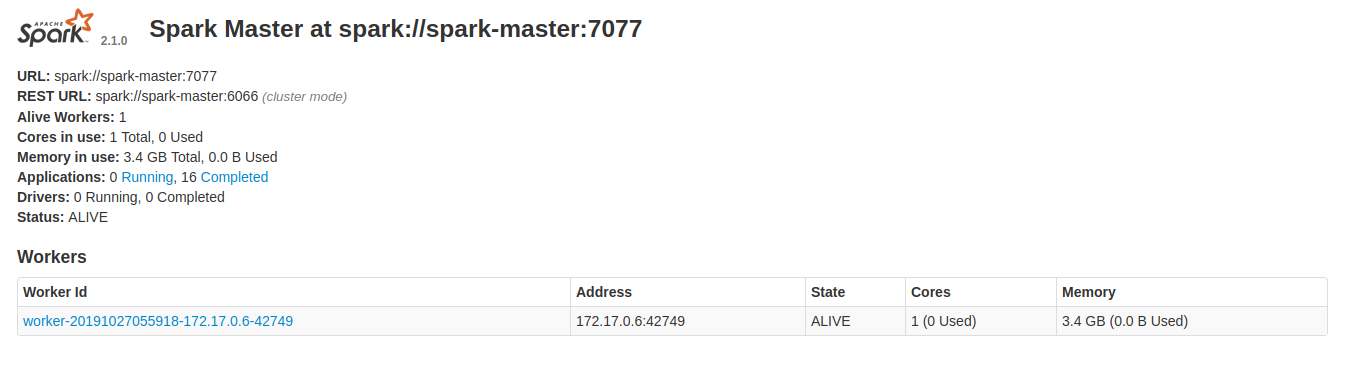 .
.
Code
You can access all the configuration and scripts on github.
Conclusion
In this post we discussed how to prepare spark cluster on kubernetes to be ready to make use of the auto scaling.