Pandas API on Apache Spark - Part 2: Hello World
Pandas API on Apache Spark brings the familiar python Pandas API on top of distributed spark framework. This combination allows python developers to write code in their favorite pandas API with all the performance and distributed benefits of spark. This marriage of API and Platform is one of the biggest improvement landing in Apache spark in recent time. This feature will be available in spark 3.2.
In these series posts we will be discussing different aspects of this integration. This is second post in the series where we will write our first hello world example. You can access other posts in the series here.
Setup
Running pandas API on spark needs Spark 3.2. At the time of this blog is written, spark 3.2 is still in the development. So to run these examples you need to build the spark tar from code. Once 3.2 is released in stable version you can use it as any other pyspark program.
You can find more details how to build code from source in below link.
https://spark.apache.org/docs/latest/building-spark.html.
Also you need to install the below libraries in your venv of python
1. Pandas >= 0.23
2. PyArrow >= 1.0Hello World
As our programming tradition, we always start with hello world example. This example can be run from pyspark console or Jupyter notebook.
The below are the steps
Import Pandas
import pyspark.pandas as psAs first step, we import pandas from pyspark project.
Create Pandas Dataframe on Spark
data = [1,2,3,4]
df = ps.DataFrame(data, columns=["a"])In above code, we create pandas dataframe using some array. As you can observe the API is exactly same python Pandas.
To make sure its using spark on pandas rather than normal pandas we can check it on spark UI.
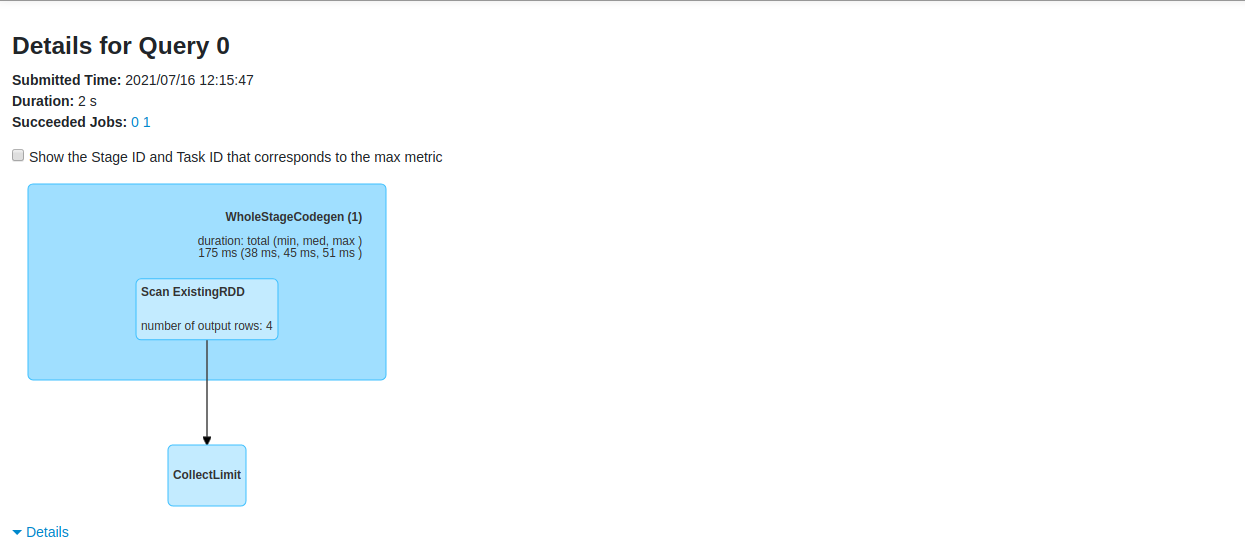
From above image, we can observe the above dataframe creation ran a SQL query on spark.
Print Data
df.head()As with normal pandas, above code prints the dataframe data.
Conclusion
In this post, we looked at how to write a simple example pandas code using Pandas API on Apache Spark.