Adaptive Query Execution in Spark 3.0 - Part 2 : Optimising Shuffle Partitions
Spark catalyst is one of the most important layer of spark SQL which does all the query optimisation. These optimisations are expressed as list of rules which will be executed on the query plan before executing the query itself. This makes sure Spark SQL can do lot more automatic optimisation compared to hand written RDD code.
Even though spark catalyst does lot of heavy lifting, it’s all done before query execution. So that means once the physical plan is created and execution of the plan started, it will not do any optimisation there after. So it cannot do some of the optimisation which is based on metrics it sees when the execution is going on.
In 3.0, spark has introduced an additional layer of optimisation. This layer is known as adaptive query execution. This layer tries to optimise the queries depending upon the metrics that are collected as part of the execution.
In this series of posts, I will be discussing about different part of adaptive execution. This is the second post in the series where I will be discussing about optimising shuffle partitions. You can find all the posts in the series here.
Spark SQL Shuffle Partitions
In Spark sql, number of shuffle partitions are set using spark.sql.shuffle.partitions which defaults to 200. In most of the cases, this number is too high for smaller data and too small for bigger data. Selecting right value becomes always tricky for the developer.
So we need an ability to coalesce the shuffle partitions by looking at the mapper output. If the mapping generates small number of partitions, we want to reduce the overall shuffle partitions so it will improve the performance.
Shuffle Partitions without AQE
Before we see how to optimise the shuffle partitions, let’s see what is the problem we are trying to solve. Let’s take below example
Read CSV and Increase Input Partitions
val df = sparkSession.read.
format("csv")
.option("header", "true")
.option("inferSchema", "true")
.load("src/main/resources/sales.csv").repartition(500)In above code, I am reading a small file and increasing the partitions to 500. This increase is to force the spark to use maximum shuffle partitions.
GroupBy for Shuffle
Once we have dataframe, let’s add group by to create shuffle
df.groupBy("customerId").count().count()Observing Stages
The below image shows the stages of the jobs.
 .
.
As you can observe from the image, stage id 4, 200 tasks ran even the data was very less.
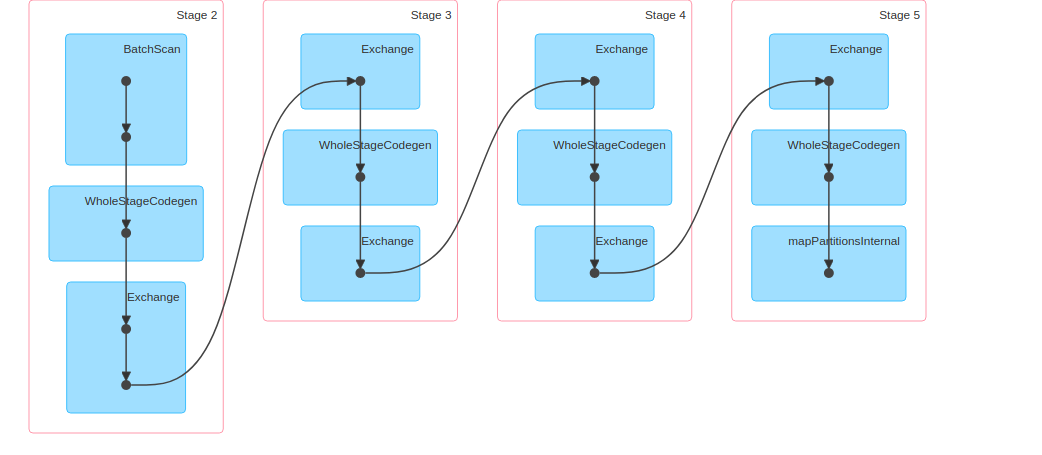
Observing DAG
The below image shows the DAG of count Job
 .
.
From the image, you can observe that there was lot of shuffle.
Optimising Shuffle Partitions in AQE
In this section of the document we talk about how to optimise the shuffle partitions using the AQE.
Enabling the configuration
To use AQE we need to set spark.sql.adaptive.enabled to true.
sparkConf.set("spark.sql.adaptive.enabled", "true")To use the shuffle partitions optimisation we need to set spark.sql.adaptive.coalescePartitions.enabled to true.
sparkConf.set("spark.sql.adaptive.coalescePartitions.enabled", "true")Rest of the code remains exactly same as above.
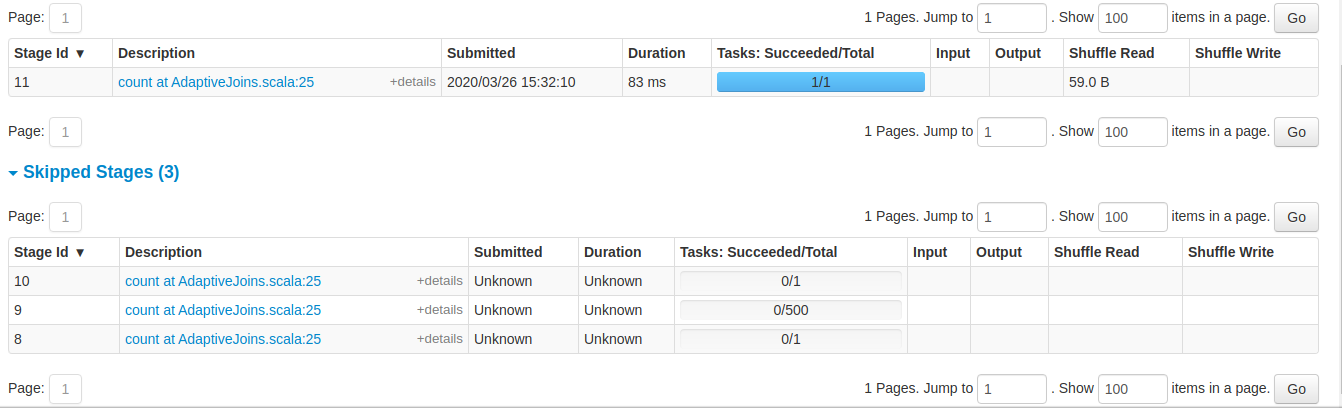
Observing Stages
The below image shows the stages of the jobs.
 .
.
From the image you can observe that, most of the stages are skipped all together as spark figured out that most of the partitions are empty.
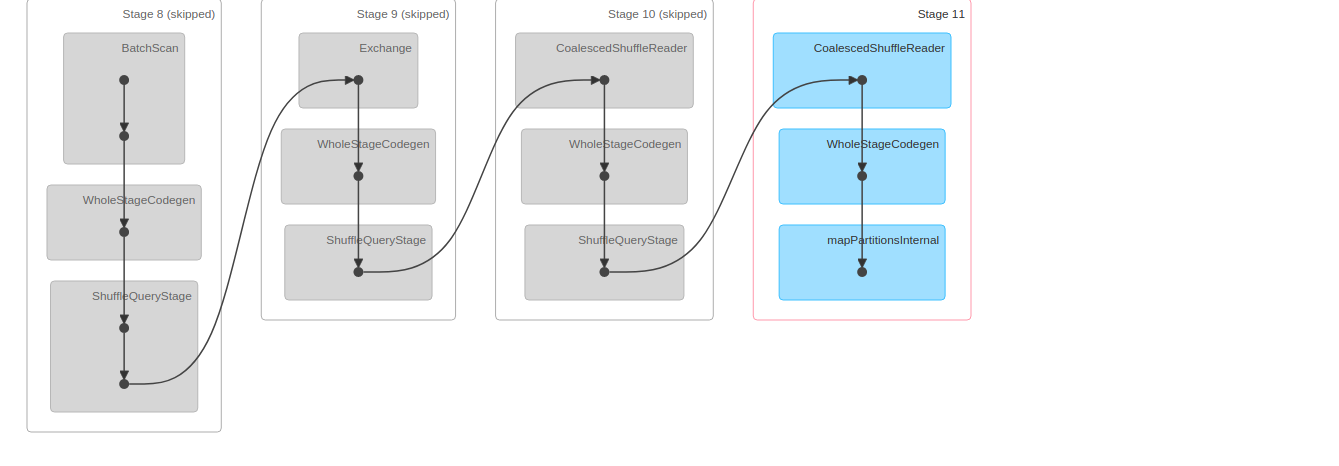
Observing DAG
The below image shows the DAG of count Job
 .
.
From the image, you can observe most of the shuffle was skipped. There is a CoalescedShuffleReader which is combining all the shuffle partitions to 1.
So by just enabling few configuration we can dynamically optimise the shuffle partitions in AQE.
Code
You can access complete code on github.