Introduction to Spark 3.0 - Part 5 : Easier Debugging of Cached Data Frames
Spark 3.0 is the next major release of Apache Spark. This release brings major changes to abstractions, API’s and libraries of the platform. This release sets the tone for next year’s direction of the framework. So understanding these few features is critical to understand for the ones who want to make use all the advances in this new release. So in this series of blog posts, I will be discussing about different improvements landing in Spark 3.0.
This is the fifth post in the series where I am going to talk about improvements in the debugging cached dataframes. You can access all posts in this series here.
TL;DR All code examples are available on github.
Challenges with Debugging Spark SQL
Lets say you are running joins on multiple datasets and trying to debug the which joins are taking time.
Let’s run below join code in 2.0
val firstDF = sparkSession.createDataFrame(Seq(
("1", 10),
("2", 20)
)).toDF("id", "sales")
firstDF.createOrReplaceTempView("firstDf")
sparkSession.catalog.cacheTable("firstDf")
val secondDF = sparkSession.createDataFrame(Seq(
("1", 40),
("2", 50)
)).toDF("id", "volume")
secondDF.createOrReplaceTempView("secondDf")
sparkSession.catalog.cacheTable("secondDf")
val thirdDF = sparkSession.createDataFrame(Seq(
("1", 70),
("2", 80)
)).toDF("id", "value")
thirdDF.createOrReplaceTempView("thirdDf")
sparkSession.catalog.cacheTable("thirdDf")
val joinDF = firstDF.join(secondDF, "id").join(thirdDF,"id")In above code, we are loading three dataframes and caching them. Then doing a simple join.
If we go to spark UI, we can see the below plan in SQL tab
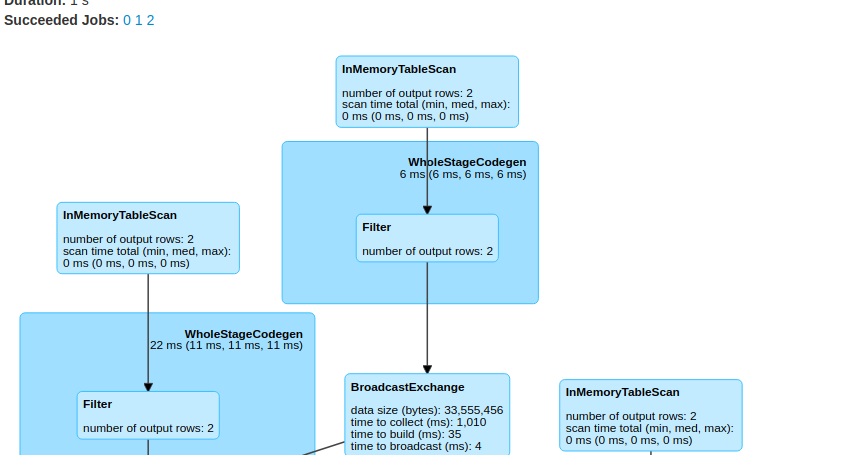
In UI everything is named as , *InMemoryTableScan**. Without name it’s very difficult to figure which tables are getting joined. If we know the join sequence its ok otherwise we need to do lot of guess work.
Improvements to Debugging in Spark 3.0
Spark 3.0 has added an improvement where it shows the name of cached table in SQL plan as below image. This greatly helps in debugging.
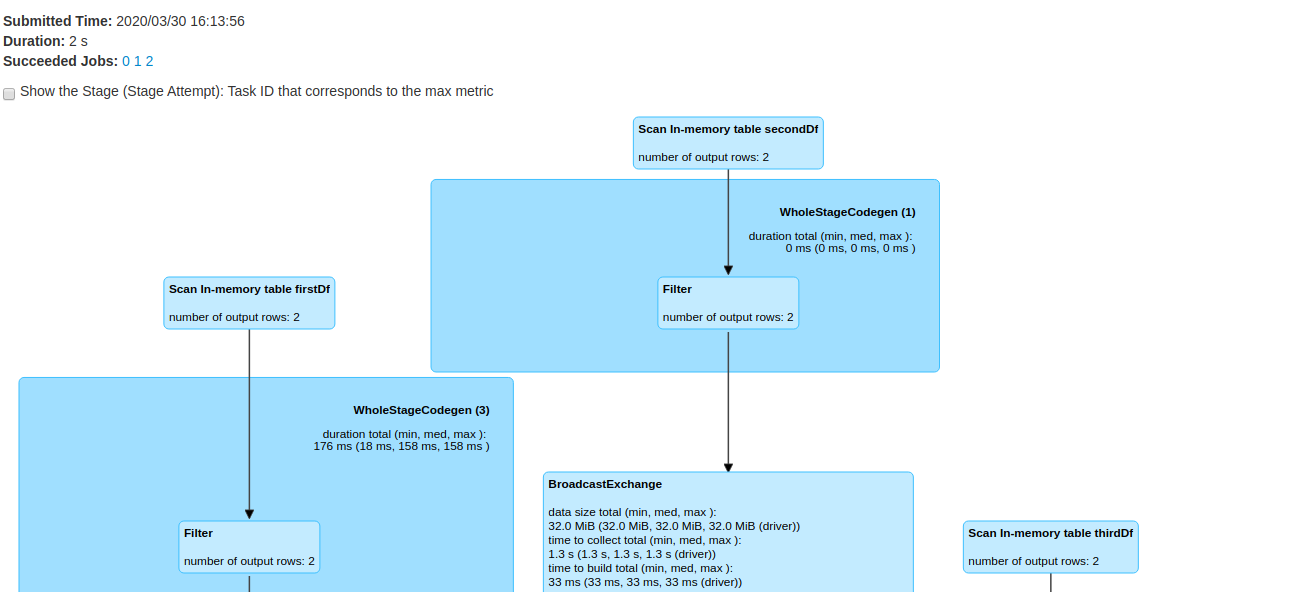 .
.
Only Works with CacheTable on Catalog API
One thing to note that, this only work if you cache the data with catalog.cacheTable API. If you cache the dataframe with cache API , these names will not show up.
Code
You can access complete code on github.