Introduction to Spark 3.0 - Part 3 : Data Loading From Nested Folders
Spark 3.0 is the next major release of Apache Spark. This release brings major changes to abstractions, API’s and libraries of the platform. This release sets the tone for next year’s direction of the framework. So understanding these few features is critical to understand for the ones who want to make use all the advances in this new release. So in this series of blog posts, I will be discussing about different improvements landing in Spark 3.0.
This is the third post in the series where I am going to talk about data loading from nested folders. You can access all posts in this series here.
TL;DR All code examples are available on github.
Data in Nested Folders
Many times we need to load data from a nested data directory. These nested data directories typically created when there is an ETL job which keep on putting data from different dates in different folder.
Let’s take below example
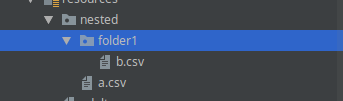
In above example, we have a.csv in the first level and b.csv which is inside folder1. Now if user want to load both the files, what they need to do?.
Loading Nested Folder in 2.x
Till 3.0, there was no direct way to load both of these together. If we loaded the directory with below code, it loads only the files in first level.
val df = sparkSession.read
.option("delimiter","||")
.option("header","true")
.csv("src/main/resources/nested")
assert(df.count() == 2)The above assertion will pass, as there are 2 rows in a.csv.
The workaround was to load both of these files separately and union them. This becomes cumbersome for large number of files.
Recursive Loading in 3.0
In Spark 3.0, there is an improvement introduced for all file based sources to read from a nested directory. User can enable recursiveFileLookup option in the read time which will make spark to read the files recursively.
val recursiveDf = sparkSession.read
.option("delimiter","||")
.option("recursiveFileLookup","true")
.option("header","true")
.csv("src/main/resources/nested")
assert(recursiveDf.count() == 4)Now the spark will read data from the both files and count will be equal to 4.
This improvement makes loading data from nested folder much easier now. The same option is available for all the file based connectors like parquet, avro etc.
Code
You can access complete code on github.