Secondary Namenode - What it really do?
Secondary Namenode is one of the poorly named component in Hadoop. By its name, it gives a sense that its a backup for the Namenode.But in reality its not. Lot of beginners in Hadoop get confused about what exactly SecondaryNamenode does and why its present in HDFS.So in this blog post I try to explain the role of secondary namenode in HDFS.
By its name, you may assume that it has something to do with Namenode and you are right. So before we dig into Secondary Namenode lets see what exactly Namenode does.
Namenode
Namenode holds the meta data for the HDFS like Namespace information, block information etc. When in use, all this information is stored in main memory. But these information also stored in disk for persistence storage.
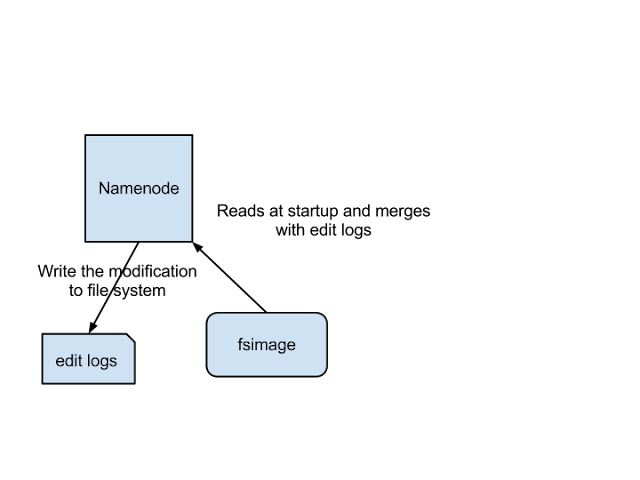
The above image shows how Name Node stores information in disk.
Two different files are
- fsimage - Its the snapshot of the filesystem when namenode started
- Edit logs - Its the sequence of changes made to the filesystem after namenode started
Only in the restart of namenode , edit logs are applied to fsimage to get the latest snapshot of the file system. But namenode restart are rare in production clusters which means edit logs can grow very large for the clusters where namenode runs for a long period of time. The following issues we will encounter in this situation.
- Editlog become very large , which will be challenging to manage it
- Namenode restart takes long time because lot of changes has to be merged
- In the case of crash, we will lost huge amount of metadata since fsimage is very old
So to overcome this issues we need a mechanism which will help us reduce the edit log size which is manageable and have up to date fsimage ,so that load on namenode reduces . It’s very similar to Windows Restore point, which will allow us to take snapshot of the OS so that if something goes wrong , we can fallback to the last restore point.
So now we understood NameNode functionality and challenges to keep the meta data up to date.So what is this all have to with Seconadary Namenode?
Secondary Namenode
Secondary Namenode helps to overcome the above issues by taking over responsibility of merging editlogs with fsimage from the namenode.
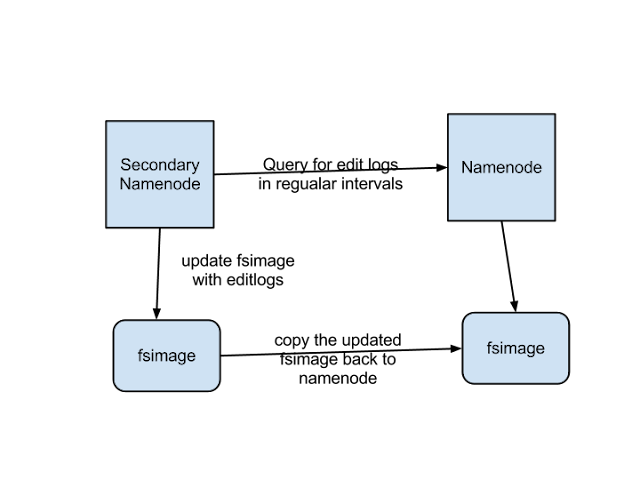
The above figure shows the working of Secondary Namenode
- It gets the edit logs from the namenode in regular intervals and applies to fsimage
- Once it has new fsimage, it copies back to namenode
- Namenode will use this fsimage for the next restart,which will reduce the startup time
Secondary Namenode whole purpose is to have a checkpoint in HDFS. Its just a helper node for namenode.That’s why it also known as checkpoint node inside the community.
So we now understood all Secondary Namenode does puts a checkpoint in filesystem which will help Namenode to function better. Its not the replacement or backup for the Namenode. So from now on make a habit of calling it as a checkpoint node.